请输入要检测的文本
输入正则表达式
匹配结果:
工具说明
工具简介
正则表达式,是一种用于字符匹配的模式,最初是由 UNIX 中的工具软件(如:sed 和 grep)普及而来的。正则表达式通常用来检索和替换那些符合某个模式或规则的文本。正则表达式测试工具,是一款用于测试和验证正则表达式的在线工具,它提供了验证正则模式(pattern)和给定的文本是否匹配的功能,并且通过高亮的方式显示匹配结果,非常直观。
本工具主要特点:
- 对输入的正则表达式提供了语法支持,可高亮显示数字、符号、通配符等
- 使用原生 JS 实现正则验证,查找和匹配的效率极高
- 匹配结果高亮显示,一目了然;同时提供了单独区域来展示匹配结果
- 提供了常用的正则表达式写法,开箱即用
特别说明:
目前,本工具暂未提供正则修饰符功能,默认使用了全局匹配修饰符g、忽略大小写修饰符i以及多行匹配修饰符m。
使用方法
在工具提供的文本框中输入正则表达式和要检测的文本,即可得到匹配结果。下面以一个简单的例子进行说明。
示例:在给定的文本中查找 Windows 10 或 Windows 11
待检测的文本如下:
Windows 10 是世界上使用最广泛的电脑操作系统,有超过 13 亿台设备正在使用。Windows 带来的收入占微软收入的 10% 以上,疫情也让 Windows 系统变得更加重要。微软此前已经宣布 Windows 10 系统将于 2025 年退役。
功能上,微软宣布,Windows 11 系统将支持 Android 应用程序,用户可通过亚马逊应用商店下载。这意味着用户可将在手机上使用的流行应用程序直接可在电脑桌面、「开始」菜单等中使用。
值得一提的是,微软宣布重新打造了速度更快的 Microsoft Store,引入更多第一及第三方应用程序,支持用户更轻松地探索应用程序、游戏、视频节目、电影等。
Windows 11 系统允许用户为生活和工作创建多个虚拟桌面,并根据自己的喜好进行定制,就像在 Mac 电脑上一样。
正则表达式如下:
windows\s*[0-9]{1,2}
匹配结果:
Windows 10
Windows 11
你可以亲自使用上面的示例文本进行测试。
为了看得更清楚,我们用一张截图来展示匹配结果(因为有高亮效果):

上图中,我们使用了蓝色和红色背景来高亮显示匹配到的字符串;而绿色椭圆框起的 Windows 字符串,并没有匹配我们给出的这个正则模式 windows\s*[0-9]{1,2},因为该正则模式要求 windows 字符串后面跟 1-2 个数字。
更严谨的正则表达式
在上面这个例子中,考虑到要检索的目标文本,使用的正则表达式 windows\s*[0-9]{1,2} 并不是特别严谨。因为该正则表达式除了匹配 Windows 10 和 Windows 11 以外,还可以匹配诸如 Windows 00、Windows 20、Windows 30、Windows 50、Windows 99 等这种字符串。如果要严格匹配 Windows 10 和 Windows 11,且只能匹配这 2 个字符串的话,正确的正则表达式写法应该是:
windows\s*[1][01]
也就是说,我们要匹配的字符串的特征是:在字符串 windows 后面首先跟一个 1(忽略那个空格 \s),然后再在 1 后面跟一个 0 或 1,因此,数字部分,结合起来就是 10 或 11 两种情况,最终达到匹配 Windows 10 和 Windows 11 的目的。
关于高亮匹配结果的补充说明
本工具交叉使用蓝色和红色来高亮显示匹配结果,是为了更好地区分每个命中的字符串,特别是当 2 个(或多个)命中结果的位置挨着一起的时候,使用不同的颜色可以更好地区分出来。比如,我们在文本第一行连续输入 3 次 Windows 10,匹配结果的显示效果如下:
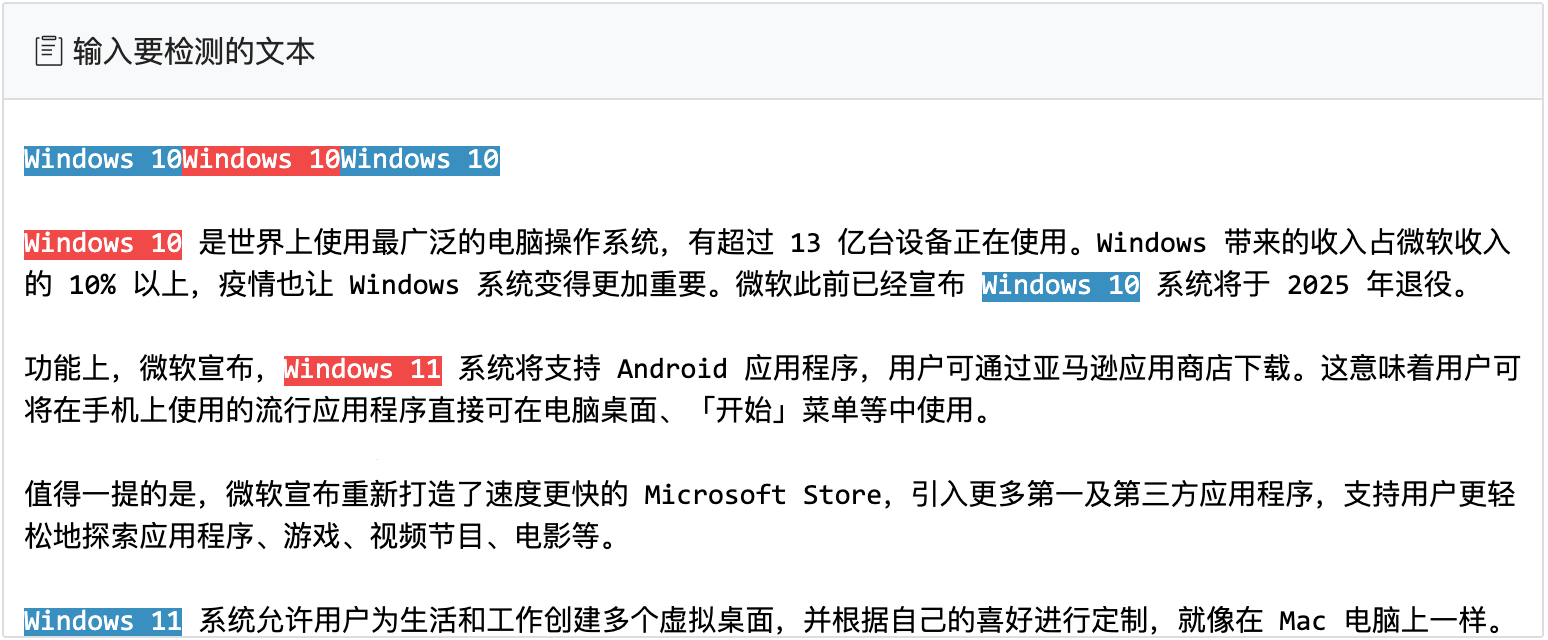
使用交叉颜色让命中结果更加一目了然。
附 1:正则表达式简介
一、发展历史
如果你曾经使用过或听说过正则表达式,就应该知道正则表达式是一种字符匹配的模式,是为检索字符这个基本需求发展起来的。但关于正则表达式更早的历史,则可以追溯至科学家对人类神经系统如何工作的早期研究。
1951 年, 一位名叫 Stephen Kleene 的数学家在 McCulloch 和 Pitts 早期工作的基础上,发表了一篇标题为《神经网事件的表示法》的论文,正式引入了正则表达式的概念。正则表达式就是用来描述他称为「正则集的代数」的表达式,因此采用「正则表达式」这个术语。
随后,Unix 主要发明人之一的肯·汤普森(Ken Thompson)发现可以将正则概念用于计算搜索算法的早期研究;正则表达式的第一个实用应用程序就是 Unix 中的 qed 编辑器。从那时起直至现在,正则表达式都是基于文本的编辑器和搜索工具中的一个重要部分。
二、应用场景
在正则表达式发展起来之前,对于搜索和替换文本这种需求,通常要求提供与预期搜索结果匹配的确切文本。这种「要求提供确切文本」的检索技术不但缺乏足够的灵活性,而且,对于某些特殊检索需求完全不能胜任。
通过使用正则表达式,则可以:
- 测试字符串内的模式
例如,可以测试输入字符串,以查看字符串内是否出现电话号码模式或信用卡号码模式 —— 这称为数据验证。 - 批量替换文本
可以使用正则表达式来识别文档中的特定文本,然后,你可以完全删除该文本或者用其他文本替换它。 - 基于模式匹配从字符串中提取子字符串
可以查找文档内或输入域内特定的文本,并单独提取出来供其它场景使用。
三、正则表达式语法
正则表达式描述了一种字符串匹配的模式,可以用来检查一段文本(或字符串)是否含有某种子字符串,并且提供了可以将匹配的子字符串替换成符合另一种字符串的功能。
正则表达式是由普通字符(例如字符 a 到 z)以及特殊字符(也称为元字符)组成的文字模式。模式描述了在检索文本时要匹配的一个或多个字符串。正则表达式作为一个模板,将某个字符模式与所搜索的字符串进行匹配。
1、普通字符
正则表达式中的普通字符,包括字母(大写和小写)、数字、汉字、下划线,以及没有特殊定义的标点符号。这些普通字符,在匹配一个字符串的时候,严格匹配与之相同的一个字符。
用法和示例:
| 字符模式 | 含义 |
|---|---|
/A/ |
匹配单个字符 A。如:/m/ 模式可以匹配字符串 memory 中出现的所有 m 字符 |
/ABC/ |
匹配字符串 ABC。如模式 /from/,在匹配字符串 select * from user 时,匹配的结果是 from |
/[ABC]/ |
匹配中括号里面的所有出现的字符。如 [irnb] 匹配字符串 npm run build 中所有的 n r b i 字母。 |
/[^ABC]/ |
和 /[ABC]/ 模式正好相反,它是匹配除了中括号里面的字符以外的所有其它字符。 |
/[A-Z]/ |
该模式表示匹配一个范围。如:[A-Z] 表示匹配所有大写字母;[a-z] 匹配所有小写字母;[0-9] 表示匹配所有数字。 |
注:在没有特殊限定符配合的情况下,均是指定匹配一个字符。
2、转义字符
在正则表达式中,也可以使用转义字符。常见的转义字符有:
\r \n:匹配回车和换行符\t:匹配文本中的制表符\v:匹配文本中的垂直制表符\f:匹配文本中的换页符\\:匹配\本身
另外,有一些标点符号在正则表达式中有特殊的含义,如:.^$ 等。当需要匹配这些符号时,需要在符号前面添加反斜杠 \ 进行转义。例如:小数点 . 在正则表达式中表示匹配任意字符,如果需要严格匹配 .,则需要对其进行转义,即使用 \. 表示 . 本身。
说明:除了正则表达式支持转义字符外,在 Web 开发中接触较多的 HTML 也提供了对转义字符的支持。关于 HTML 中的转义字符,可以参考 HTML 转义字符 大全。
3、表示一类字符的字符
在正则表达式中,一些特殊的模式可以表示匹配一类字符中的任意一个字符。比如,表达式 \d 可以匹配任意一个数字,等价于 [0-9]。
下表列出了常见的可以表示一类字符的字符。
| 模式 | 含义 |
|---|---|
\d |
匹配任意一个数字,即 0-9 之间的任意一个数字 |
\w |
匹配任意一个字母、数字或下划线,也就是 A-Z、a-z、0-9 和 _ 中的一个 |
\s |
匹配任何空白字符,包括空格、制表符、换页符等 |
\S |
和 \s 功能相反,它匹配任何非空白字符 |
. |
匹配除换行符 \n 以外的任意一个字符 |
4、匹配次数限定符
匹配次数限定符,是用来指定正则表达式的一个给定组件必须要出现多少次才能满足匹配条件。这些用于表示匹配次数的限定符包括:
| 限定符 | 含义 |
|---|---|
* |
匹配 0 次或多次它前面的子表达式。如:go*d 能匹配 gd、god 以及 good |
+ |
匹配 1 次或多次它前面的子表达式。如:spe*d 能匹配 sped、speed 以及 speeed,但不能匹配 spd |
? |
匹配 0 次或 1 次它前面的子表达式。如:t(ea)?m,可以匹配 tm,也可以匹配 team。注:可以把 ? 限定符理解为 {0,1} |
{n} |
该表达式使用了大括号,括号中间的 n 是一个非负整数,表示匹配 n 次它前面的子表达式。如:Macbo{2}k,不能匹配 Macbok,因为只出现了一次 o,但是可以匹配 Macbook 中的 2 个 o |
{n,} |
大括号中间的 n 是一个非负整数,该表达式表示至少匹配 n 次子表达式。如:ht{2,}p,不能匹配 htp 中的 t,但可以匹配 http、htttp、httttp,因为 t 出现了 2 次及以上 |
{n,m} |
在该表达式中,n 和 m 均为非负整数(要求 n <= m),其含义是对于它前面的子表达式,最少匹配 n 次,最多匹配 m 次。如:[0-9]{5,11} 这个表达式,表示对于数字 0-9,要求最少 5 位,最多 11 位才能匹配成功。呐,这不是 QQ 号码的正则表达式嘛! |
特别说明:
*、+和?限定符都是贪婪匹配的,因为它们会尽可能多的匹配文字,只有在它们的后面再加一个?符号,就可以实现非贪婪或最小匹配。下面,我们以匹配 HTML 文档中的 H1 标签为例,对贪婪匹配和非贪婪匹配进行说明。
H1 标签内容如下:
<h1>独特工具箱</h1>。如果我们要匹配h1标签,那么:
- 贪婪匹配使用的正则表达式是:
/<.*>/。该表达式将从开始的小括号<开始一直搜索,直到h1结束标签的那个大括号>才结束。也就是说,/<.*>/这个表达式将匹配从开始的<h1>标签到结束的</h1>为止。- 非贪婪匹配使用的正则表达式是:
/<.*?>/。该表达式只会匹配开始的那个<h1>标签,不会再往后面继续检索了。
5、定位符
定位符用来描述字符串或单词的边界,使你能够将正则表达式固定到行首或行尾。正则表达式的定位符是一个功能十分强大的特性,通过定位符,可以方便地检索指定位置的单词。
正则表达式的定位符有:^、$、\b 和 \B,下表对这几个定位符进行了说明。
| 定位符 | 含义 |
|---|---|
^ |
匹配输入字符串开始的位置。如果设置了 Multiline 属性,^ 还会与 \n 或 \r 之后的位置匹配。 |
$ |
匹配输入字符串结尾的位置。如果设置了 Multiline 属性,$ 还会与 \n 或 \r 之前的位置匹配。 |
\b |
匹配一个单词边界,即字符与空格间的位置。 |
\B |
和 \b 相反,非单词边界匹配。 |
例如,正则表达式 ^http:\/\/ 表示对于待检索的字符串,要求以 http:// 开头,才能正确匹配;而对于 \.php$ 这个正则表达式,要求待检索待字符串必须以 .php 结尾才能正确匹配。
特别说明:
不能将限定符与定位符一起使用。由于在紧靠换行或者单词边界的前面或后面不能有一个以上位置,因此不允许出现
^+这种的表达式。
6、分组和选择
正则表达式也提供了分组和选择的功能。其中,圆括号 () 表示捕获分组,并且可以单独得到通过 () 匹配到的内容;| 表示选择,它左右两边的子表达式是一种“或”关系,即被 | 分隔的子表达式,只要其中之一满足匹配条件,则匹配成功。
7、正向预查和反向预查
由分组衍生出正向预查和反向预查两个概念。
正向预查
正向预查,是指在任何开始匹配圆括号内的正则表达式模式的位置来匹配搜索字符串,其语法是在子模式内部前面加 ?=,意思是:1、要匹配的文本必须满足此子模式前面的表达式;2、此子模式不参与匹配。
例如,我们需要在一段文本中查找 Windows 字符串,并且要求只查找 Windows 后面的版本号是数字的情况,不能是字母。也就是说,我们希望查找 Winodws 7、Windows 10 这种版本号是数字的情况,而忽略 Windows NT、Windows XP、Windows Vista 这种版本号是字母的情况。
那么,基于上述要求,可以通过 Windows(?= [\d.]+\b) 这个正则表达式来满足该需求。匹配结果如下图所示:

反向预查
反向预查,指在任何结束的地方匹配该正则表达式模式的位置来匹配搜索字符串,其语法是在子模式内部前面加 ?<=,意思是:1、要匹配的文本必须满足此子模式后面的表达式;2、此子模式不参与匹配。
例如,我们要匹配下面这段文本中属于 CNY 的金额(不含 CNY):
CNY: 128.04
USD: 22.5
USD: 23.5
HKD: 1533.5
CNY: 23.78
要达到上述要求,正则表达式正确的写法是:(?<=CNY: )\d+\.\d+。匹配结果如下图所示:

除了正向预查和反向预查,还有对应的正向否定预查 ?! 和反向否定预查 ?<!,有兴趣的可以自行查找资料深入了解其用法。
附 2:常用正则表达式
下面列出了我们日常开发中常用的正则表达式,希望对你有用。
1、匹配电子邮箱地址
\w[-\w.+]*@([A-Za-z0-9][-A-Za-z0-9]+\.)+[A-Za-z]{2,14}
2、匹配 URL
https?:\/\/(www\.)?[-a-zA-Z0-9@:%._\+~#=]{2,256}\.[a-z]{2,6}\b([-a-zA-Z0-9@:%_\+.~#?&//=]*)
3、匹配十六进制颜色
#?([a-fA-F0-9]{6}|[a-fA-F0-9]{3})
本站提供了颜色转换工具,用于在十六进制颜色和 RGB/HSL/HSV 颜色之间转换。
4、匹配国内手机号码
1([38][0-9]|4[579]|5[0-3,5-9]|6[6]|7[0135678]|9[89])\d{8}
5、匹配国内 18 位身份证号码
\d{17}[\d|x]
本站提供了以下 2 个和身份证号码相关的工具:
- 身份证信息查询工具:可以根据身份证号码查询对应的发证省份、城市、地区、出生年月日、性别、年龄等。
- 虚拟身份证号码生成工具:可以根据指定的条件,如:出身地、出身日期、性别等生成符合中国大陆 GB 11643-1999 国标的身份证号码。
6、匹配 IPv4 地址
(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)
要查 IP 地址?请使用 IP 地址查询 工具。
7、匹配 IPv6 地址
(([0-9a-fA-F]{1,4}:){7,7}[0-9a-fA-F]{1,4}|([0-9a-fA-F]{1,4}:){1,7}:|([0-9a-fA-F]{1,4}:){1,6}:[0-9a-fA-F]{1,4}|([0-9a-fA-F]{1,4}:){1,5}(:[0-9a-fA-F]{1,4}){1,2}|([0-9a-fA-F]{1,4}:){1,4}(:[0-9a-fA-F]{1,4}){1,3}|([0-9a-fA-F]{1,4}:){1,3}(:[0-9a-fA-F]{1,4}){1,4}|([0-9a-fA-F]{1,4}:){1,2}(:[0-9a-fA-F]{1,4}){1,5}|[0-9a-fA-F]{1,4}:((:[0-9a-fA-F]{1,4}){1,6})|:((:[0-9a-fA-F]{1,4}){1,7}|:)|fe80:(:[0-9a-fA-F]{0,4}){0,4}%[0-9a-zA-Z]{1,}|::(ffff(:0{1,4}){0,1}:){0,1}((25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])\.){3,3}(25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])|([0-9a-fA-F]{1,4}:){1,4}:((25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])\.){3,3}(25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9]))
8、匹配 时:分:秒 时间
([01]?\d|2[0-3]):[0-5]?\d:[0-5]?\d
9、匹配 年-月-日 日期
(([0-9]{3}[1-9]|[0-9]{2}[1-9][0-9]{1}|[0-9]{1}[1-9][0-9]{2}|[1-9][0-9]{3})-(((0[13578]|1[02])-(0[1-9]|[12][0-9]|3[01]))|((0[469]|11)-(0[1-9]|[12][0-9]|30))|(02-(0[1-9]|[1][0-9]|2[0-8]))))|((([0-9]{2})(0[48]|[2468][048]|[13579][26])|((0[48]|[2468][048]|[3579][26])00))-02-29)
10、匹配汉字
[\u4e00-\u9fa5]
11、匹配车牌号(包括新能源汽车车牌)
^[京津沪渝冀豫云辽黑湘皖鲁新苏浙赣鄂桂甘晋蒙陕吉闽贵粤青藏川宁琼使领]{1}[A-HJ-NP-Z]{1}(?:(([0-9]{5}[DF])|([DF][A-HJ-NP-Z0-9][0-9]{4}))|[A-HJ-NP-Z0-9]{4}[A-HJ-NP-Z0-9挂学警港澳]{1})$
想了解全国各省市区车牌号?全国车牌号简称提供了这方面的知识。